The Science
Built to be measured.
We do not ask you to trust the Behaviour Code because a famous psychologist once drew a similar map. We ask you to judge it by whether it works, and we built it to be measured. Here is the argument, and the evidence beneath it.
I · The premise
We are pattern-reading animals
Long before anyone wrote a personality test, survival depended on reading other people fast. Face detection is present within hours of birth. In the classic thin-slice studies, observers who watched a few seconds of silent footage formed judgments that matched those of people who had spent a whole semester in the room. Daniel Kahneman named the faculty responsible: System 1, the fast, intuitive mode that reaches a verdict before the deliberate mind has finished its first sentence.
So identity is not a private fact waiting to be excavated by a long questionnaire. It is a signal, broadcast constantly and read in a glance. Archetypes are simply the names our social brains already use for the patterns we evolved to recognize. Not mysticism. The compression format of human social cognition. Which is why a result that cannot be grasped at a glance has already failed, however clever its math.
II · The architecture
Three drives, two traditions
Beneath the twelve patterns sit three drives. They are not chosen for elegance. They converge with McClelland's three social motives, derived independently through decades of motivation research. When two traditions arrive at the same three forces, that convergence is itself evidence.
Care
the drive to connect, support, and heal.
Need for affiliation
Create
the drive to make, imagine, and express.
Need for achievement
Conquer
the drive to lead, win, and rise.
Need for power
III · The method
An aggregator, not an invention
The Behaviour Code does not claim a new law of personality. There is no such law to discover. What it does is aggregate the most validated and effective methods in the field and collide them with a single purpose: revealing the self at its best. Each one earns its place.
Jungian / Pearson archetypes
A vocabulary of figures people recognize on sight. We hold it as hypothesis, then sharpen it until each pattern is measurably distinct.
Big Five / OCEAN
The field's benchmark for reliability and validity. We borrow the rigor and return a self you can act from, not thirty percentile scores.
McClelland's three motives
The empirical grounding for the three drives: achievement, affiliation, power.
Forced-choice / MaxDiff
Every answer is a trade-off, which defeats the social-desirability bias and straight-lining that sink ordinary self-report.
Item Response Theory
Weight each trait by how sharply it discriminates. This is what the Trait-Value engine computes.
Thin-slicing / System 1
The science of fast, accurate person-perception, made our design rule: the result must read at a glance.
Self · Perceived · Lived
Three perspectives, the way 360s work. The gap between intent and impact becomes one tracked number: Coherence.
Strengths-based
Build from what is best, not what is broken. The whole instrument optimizes for the self at its best.
From identity to contribution
The same three drives are the three phases of any piece of work. That arc sits, under different names, beneath every serious model of how teams contribute.
Read them and the convergence is unmistakable: idea, then drive, then deliver. That is Create, Conquer, Care. One difference is worth naming: the established models lean toward idea and execution and under-weight the human, delivery half. Because Care is a full drive here, the People and Delivery phase is first-class, precisely the half that decides whether good work ever lands.
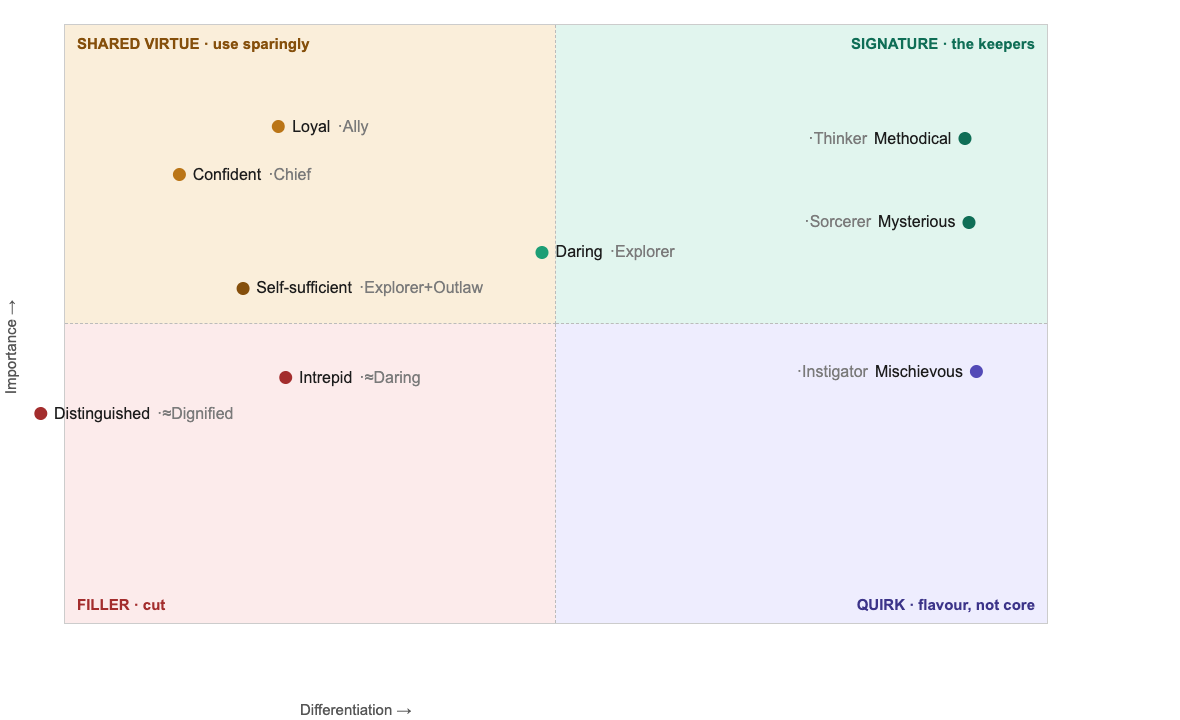
IV · The proof
Every trait earns its place
We score every trait on two axes: how uniquely it flags one archetype (Differentiation), and how central it is to that archetype at its best (Importance). The keepers sit top-right. Shared virtues and near-synonyms fall to the cut zone, and we remove them.
V · For the skeptic
The criteria that matter
Validity, reliability, fairness, the standards a serious buyer screens on. Here is how the instrument meets each, including where we are still earning the evidence.
Construct validity
A differentiation engine scores how uniquely each trait flags one archetype. A category that blurs into its neighbour is, by design, a category we fix. Most archetype tools never test this.
Reliability
Forced-choice end to end suppresses the response styles that make type tests flip, where a third to three-quarters of people get a different result within weeks.
The Barnum test
A trait that describes everyone scores zero on differentiation and is cut. We are, in a precise sense, engineered against horoscopes.
Criterion validity
Built in the open, through a calibration study and a resonance signal on every read. We do not claim predictive power we have not yet earned.
Fairness
The three modes change only the framing of a question, never the scoring. No protected-class inputs. Impression management buys you little.
VI · The honest foundation
No taxonomy has a validated bedrock. So we earn it.
Not the archetypes, which are a heritage rather than a proof. Not even the Big Five entirely, which is a model, not a law. It is turtles all the way down. Most vendors hide this behind a famous name. We will not. If there is no bedrock to stand on, the only honest test left is whether the instrument works, and that is a harder bar than “scientifically validated,” not a softer one. A citation can be borrowed. Usefulness cannot be faked.
Read the full white paper